•
생각보다 PyTorch에서 learning rate scheduler를 커스텀하게 구현하는 방법이 간단하지는 않다.
•
이 기회에 PyTorch의 learning rate scheduler들이 어떻게 구현되어 있는지 공부하기 위해서, learning rate가 특정 값까지 linear하게 상승했다가 다시 linear하게 감소하는 LinearAnnealingScheduler를 직접 구현해보려고 한다.
torch.optim.lr_scheduler.LRScheduler base class
•
모든 PyTorch 내의 learning rate scheduler들은 torch.optim.lr_scheduler.LRScheduler 베이스 클래스를 상속한다.
•
따라서 커스텀하게 learning rate scheduler를 만들고자 할 때도 이 클래스를 상속 후 적당하게 필요한 learning rate schedule 관련 메소드를 오버라이딩해서 쓰면 될 것이다.
•
그럼, LRScheduler 클래스가 어떻게 구현되어 있는지 확인해 보자.
◦
코드를 읽으며, 주요 method 에 대해 쉬운 언어로 comment를 재작성 해본다.
__init__
class LRScheduler:
def __init__(self, optimizer, last_epoch=-1, verbose=False):
# Scheduler가 lr을 조절하는 optimizer를 할당.
if not isinstance(optimizer, Optimizer):
raise TypeError('{} is not an Optimizer'.format(
type(optimizer).__name__))
self.optimizer = optimizer
# Scheduler는 optimizer param_group 중
# 'initial_lr'이라는 key를 learning rate scheduling에 활용한다.
#
# last_epoch으로 -1이 주어지면 (대부분의 경우가 이 경우)
# 현재 optimizer의 각 param_group의 'lr' 값을 initial_lr로 사용한다.
if last_epoch == -1:
# Optimizer
for group in optimizer.param_groups:
group.setdefault('initial_lr', group['lr'])
# last_epoch으로 다른 값이 주어지면 scheduling을 위해
# optimizer 각 param_group 내에 이미 initial_lr이 정의되어 있어야 한다.
# 만약 아니라면, error를 발생시키고 끝낸다.
else:
for i, group in enumerate(optimizer.param_groups):
if 'initial_lr' not in group:
raise KeyError("param 'initial_lr' is not specified "
"in param_groups[{}] when resuming an optimizer".format(i))
# 각 param_group에 대해서 initial_lr 값의 리스트를 가지고 있는다.
self.base_lrs = [group['initial_lr'] for group in optimizer.param_groups]
self.last_epoch = last_epoch
# Following https://github.com/pytorch/pytorch/issues/20124
# We would like to ensure that `lr_scheduler.step()` is called after
# `optimizer.step()`
def with_counter(method):
# 이미
if getattr(method, '_with_counter', False):
# `optimizer.step()` has already been replaced, return.
return method
# Optimizer instance에 대한 cyclic reference를 방지하기 위해서 weak reference를 사용한다.
instance_ref = weakref.ref(method.__self__) # Optimizer instance 자체에 대한 reference.
# Get the unbound method for the same purpose.
func = method.__func__
cls = instance_ref().__class__
del method
@wraps(func)
def wrapper(*args, **kwargs):
instance = instance_ref()
instance._step_count += 1
wrapped = func.__get__(instance, cls)
return wrapped(*args, **kwargs)
# Note that the returned function here is no longer a bound method,
# so attributes like `__func__` and `__self__` no longer exist.
wrapper._with_counter = True
return wrapper
# 위의 with_counter 라는 wrapper 덕분에 optimizer instance와 step 메소드는 아래와 같이 변형된다.
#
# 1. optimizer instance는 _step_count 변수를 가지며, 이 변수는 optimizer.step 메소드가 실행될 때마다 1씩 증가한다.
# 2. optimizer.step method는 '_with_counter' 라는 attribute를 가지며, 값이 True로 정해진다.
#
self.optimizer.step = with_counter(self.optimizer.step)
self.verbose = verbose
self._initial_step()
Python
복사
_initial_step(self)
def _initial_step(self):
# Optimizer와 이 scheduler의 `_step_count` 변수를 0으로 초기화하고
# scheduler의 step을 한번 진행한다.
self.optimizer._step_count = 0
self._step_count = 0
self.step()
Python
복사
get_lr(self)
def get_lr(self):
# Compute learning rate using chainable form of the scheduler
#
# 이 클래스를 상속받아 custom scheduler를 구현 시 이 메소드를 잘 override 해서 구현해야할 것.
raise NotImplementedError
Python
복사
step(self, epoch=None)
•
optimizer의 param_group의 lr 값을 새로운 값으로 바꿔주는 logic이기만 하면, 얼마든지 overriding이 가능한 것으로 보인다.
•
get_lr만 잘 구현해두고, 필요 시에만 overriding 하면 될 듯?
def step(self, epoch=None): # 참고로 step 메소드 호출 시 epoch 파라미터를 넘겨주는 방식은 이제 사용하지 않는 편이 좋다.
# 첫 step 실행 시에 검사:
if self._step_count == 1:
# optimizer.step이 _with_counter attribute을 안 가지는 상황. Initialization에 문제가 있다.
if not hasattr(self.optimizer.step, "_with_counter"):
warnings.warn("Seems like `optimizer.step()` has been overridden after learning rate scheduler "
"initialization. Please, make sure to call `optimizer.step()` before "
"`lr_scheduler.step()`. See more details at "
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
# optimizer.step()이 실행되기 전에 lr_scheduler.step()이 실행된 경우.
elif self.optimizer._step_count < 1:
warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. "
"In PyTorch 1.1.0 and later, you should call them in the opposite order: "
"`optimizer.step()` before `lr_scheduler.step()`. Failure to do this "
"will result in PyTorch skipping the first value of the learning rate schedule. "
"See more details at "
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
# scheduler의 _step_count를 증가시킨다.
self._step_count += 1
with _enable_get_lr_call(self):
if epoch is None:
self.last_epoch += 1
values = self.get_lr()
else:
warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning)
self.last_epoch = epoch
if hasattr(self, "_get_closed_form_lr"):
values = self._get_closed_form_lr()
else:
values = self.get_lr()
for i, data in enumerate(zip(self.optimizer.param_groups, values)):
param_group, lr = data
param_group['lr'] = lr
self.print_lr(self.verbose, i, lr, epoch)
self._last_lr = [group['lr'] for group in self.optimizer.param_groups]
Python
복사
LinearAnnealingLR 구현
•
get_lr 메소드 내에서, self.base_lrs 변수를 바탕으로 learning rate만 구해주는 식으로 아래와 같이 간단히 구현해낼 수가 있다.
•
상속 시에는 torch.optim.lr_scheduler 내의 _LRScheduler 를 상속해야 한다. 맨 앞의 underscore에 조심하자.
from torch.optim.lr_scheduler import _LRScheduler
class LinearAnnealingLR(_LRScheduler):
def __init__(self, optimizer, num_annealing_steps, num_total_steps):
self.num_annealing_steps = num_annealing_steps
self.num_total_steps = num_total_steps
super().__init__(optimizer)
def get_lr(self):
if self._step_count <= self.num_annealing_steps:
return [base_lr * self._step_count / self.num_annealing_steps for base_lr in self.base_lrs]
else:
return [base_lr * (self.num_total_steps - self._step_count) / (self.num_total_steps - self.num_annealing_steps) for base_lr in self.base_lrs]
Python
복사
테스트
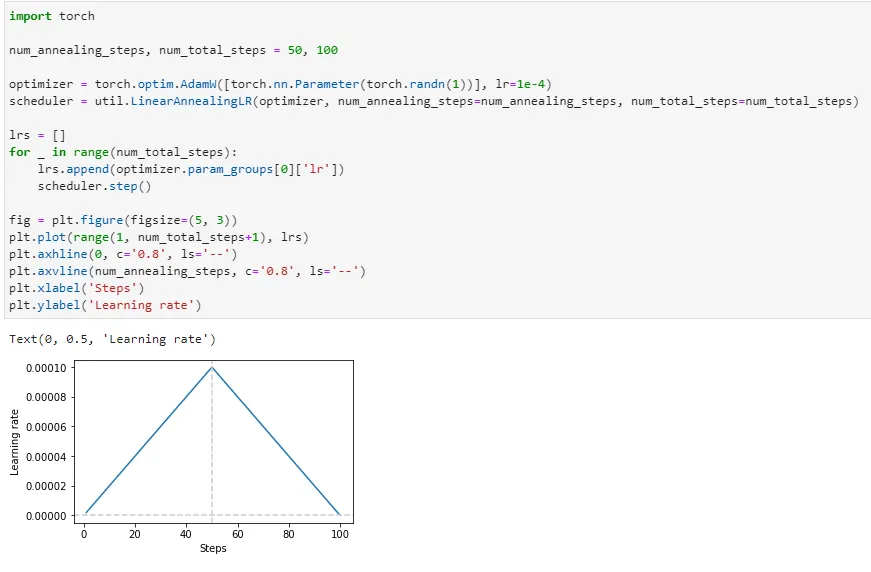
•
num_annealing_steps=50, num_total_steps=100
•
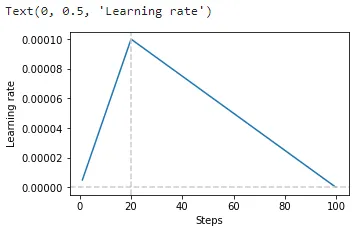
num_annealing_steps=20, num_total_steps=100
•
num_annealing_steps=20, num_total_steps=1000