

PyTorch DataLoader Sampler 사용법
Sampler에서 생각할 것은 간단하다. Dataset 내의 data의 index를 어떻게 sampling하여 다음 iteration에 yield할 것인지 판단해주는 함수만 구현하면 된다.
Custom sampler class를 구현할 떄는 __iter__ 와 __len__ 을 구현하면 된다.
예시 1) Batch 내 Class balance가 맞도록 sampling하기
다음과 같은 Imbalanced class (80:20) 를 갖는 ImbalancedDataset이 있다고 하자.
class ImbalancedDataset(Dataset):
def __init__(self):
super(ImbalancedDataset, self).__init__()
# Dummy features.
self.data = torch.randn([10000])
# Dummy imbalanced labels with 80% of 0's and 20% of 1's.
self.target = (torch.randn([10000]) > 0.8).long()
def __getitem__(self, i):
return self.data[i], self.target[i]
def __len__(self):
return len(self.data)
def get_targets(self):
return self.target
Python
복사
Naive sampling
이 Dataset을 naive하게 DataLoader로 sampling하게 되면 각각의 batch는 당연히 label 0:1 = 80:20 비율로 샘플링 될 것이다.
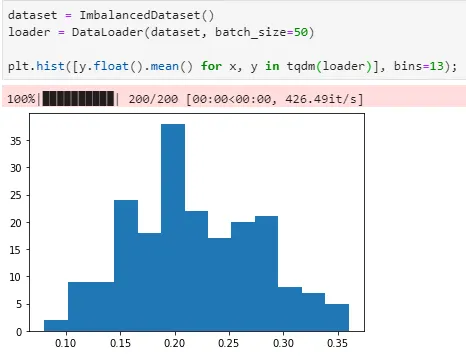
예상대로 각 batch 당 y=1 인 데이터의 비율이 0.2 근방에 존재함
NaiveBalancedSampler 구현
아래와 같이 sampler가 Dataset 내 각 데이터의 label 값을 보고 해당 데이터를 얼마의 확률로 sampling할 것인지를 판단하게 하면, 하나의 batch 내에 존재하는 데이터 label의 비율을 조절할 수 있을 것이다.
from torch.utils.data import Sampler
class NaiveBalancedSampler(Sampler):
def __init__(self, dataset):
super(NaiveBalancedSampler, self).__init__(dataset)
self.indices = np.arange(len(dataset))
self.targets = pd.Series(dataset.get_targets())
self.p_class = self.targets.value_counts(normalize=True)
# Compute sampling probabilities.
self.p = (1 / self.targets.map(self.p_class)).values
self.p /= self.p.sum()
def __iter__(self):
for _ in range(len(self.indices)):
# Randomly sample indices according to
# the probabilities computed before.
yield np.random.choice(self.indices, p=self.p)
def __len__(self):
return len(dataset)
Python
복사
이 sampler를 이용하여 DataLoader를 만들어 사용하면 다음과 같이 각 batch 의 label 균형을 맞춰줄 수 있다.
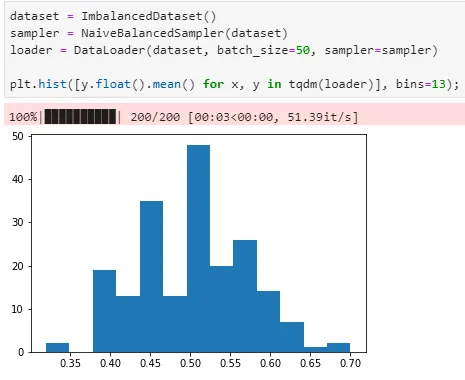
여기서 문제점이 있다. 매 iteration마다 np.random.choice를 부르기 때문에 속도가 매우 느려진다는 거다. 해결책은 그냥 PyTorch에서 제공하는 WeightedRandomSampler를 이용하는 것이다ㅋㅋ
결론: WeightedRandomSampler를 쓰자
편한 것은 weight들의 합이 꼭 1이 될 필요가 없다는 것이다. 즉 class 내 데이터 개수의 역수를 weight 로 주면 한 batch 내에 평균적으로 모든 class가 균등하게 들어가게 된다.
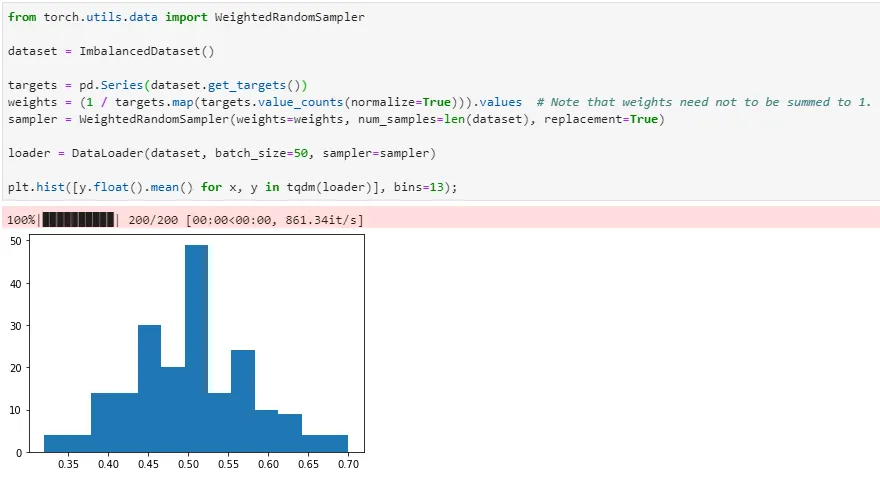
금방 끝난다
replacement=True를 주면 한번 뽑았던 샘플이 또 뽑히게 되는데, 그러면 한 epoch에서 보는 dataset의 effective size가 작아지는 것이 아닌가? 확인해보자.
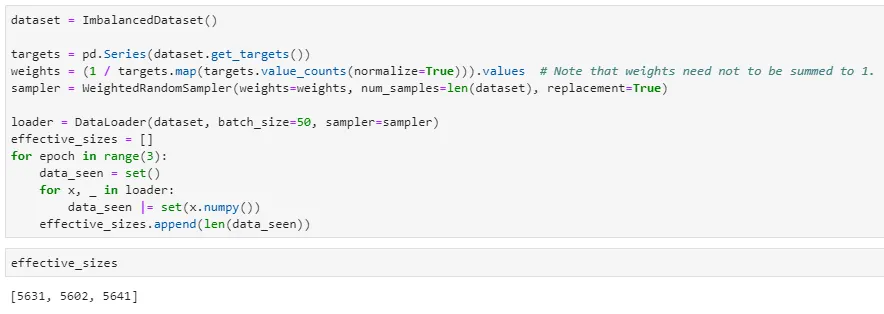
확실히 dataset의 effective size가 줄어드는 경향이 보인다. Trade-off라고 생각해야 될 듯
예시 2) Regression에서 사용하는 방법?
사실 이렇게 정리하게 된 계기이긴 한데, regression 문제에서 target 값의 imbalance가 심할 때 어떻게 sampling하면 좋을까 고민한 결과, target 값을 binning해서 sampling하는 것이 그나마 feasible한 방법으로 생각되었다. 아래와 같은 toy example로 테스트해보겠다.
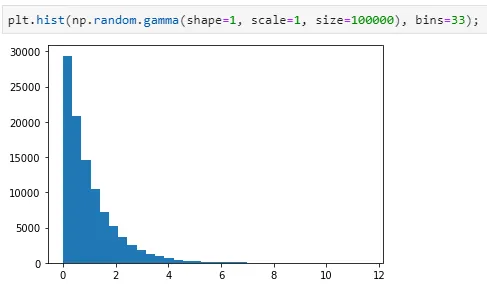
Imbalanced target y로는
을 따르는 값들을 sampling하여 사용하였다.
값들을 binning하여 정리하는 건 pd.cut 을 이용하고, bin 개수는 일단 임의로 100개로 설정하였다. 그 결과 아래와 같이 꽤나 균등하게 sampling이 되고 있음을 알 수 있다.
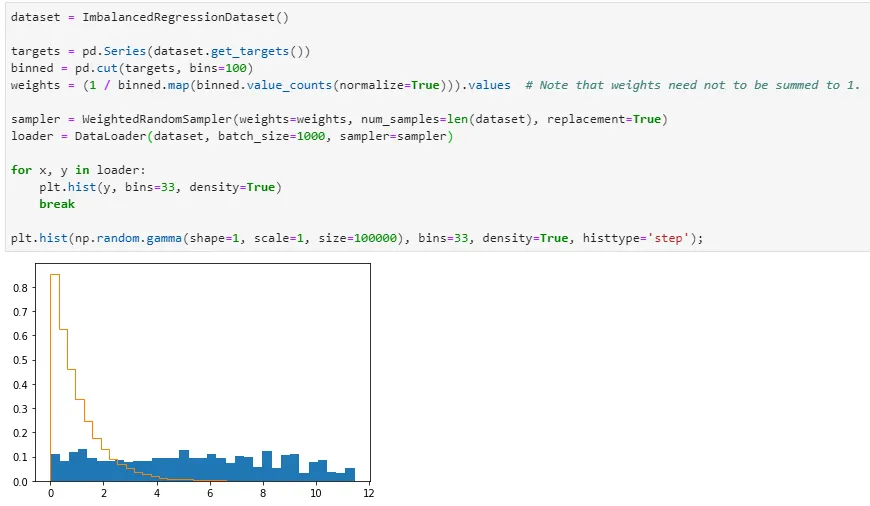
이걸 적용해서 training을 해보자. Bin 개수가 너무 자잘하면 오히려 training에 방해가 될 것 같으니... 몇 번 trial & error를 해서 최적의 bin 개수를 대충 찾아보자.