


생물정보학 연구에 있어서 텍스트 파일을 읽고 수정하는 등 빠르게 처리하는 것은 매우 중요하다. 이를 위해 대학원 신입생 시절 GitHub에 정리해둔 SED 학습 문서(https://github.com/dohlee/learn-sed#regular-expressions)를 옮겨왔다.
Contents
•
What is SED?
SED stands for Stream EDitor, developed by Lee E. McMahon of Bell Labs. SED can be used for text manipulation, such as text substitution, selective line deletion, and selective line output. Although there exists another powerful stream editing tool, awk, you still can solve any text transformation task with SED. In this tutorial, we will focus on solving many real-life task with SED.
SED cycle
You should be acquainted with the workflow of SED in order to write your SED codes proficiently. When you type SED commands and hit ENTER , the internal structure of SED program looks as below:
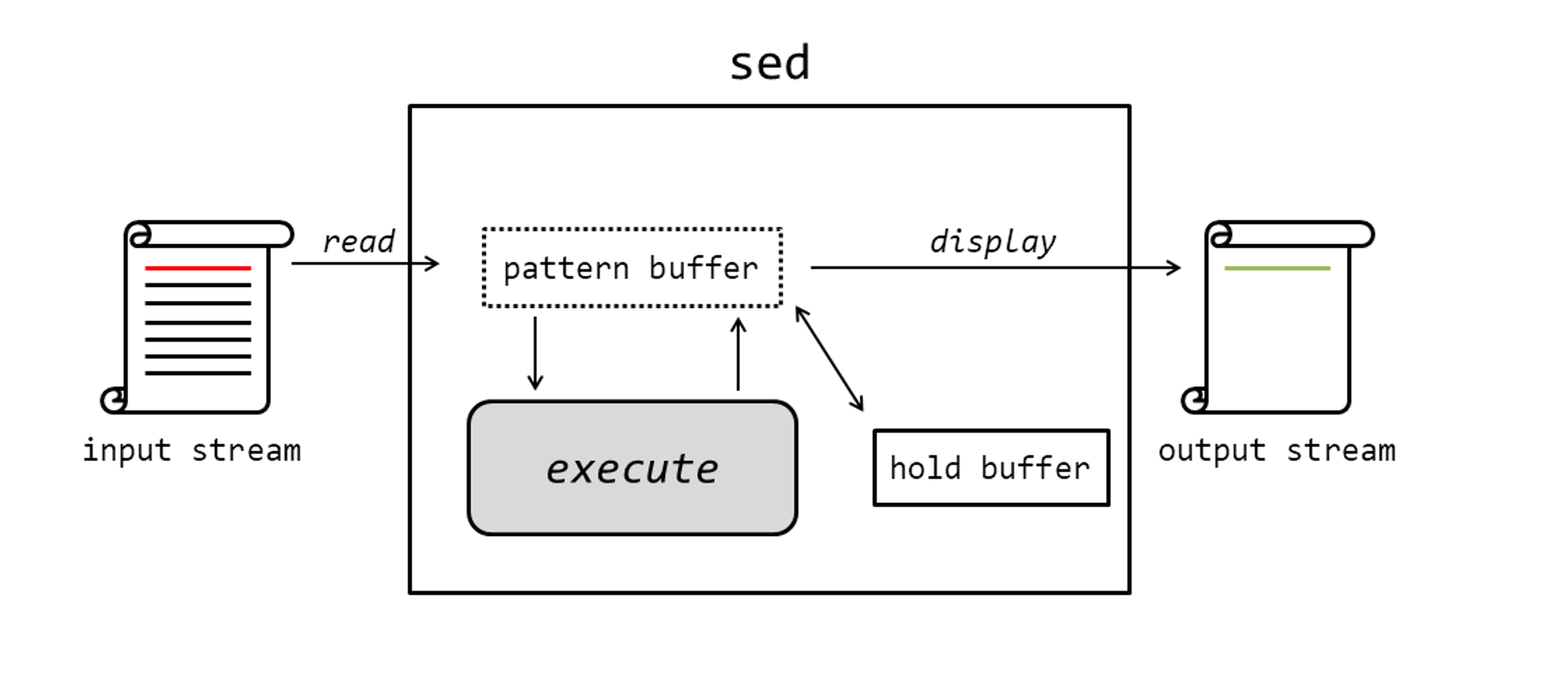
Details
1.
Read: Read a line from input stream(e.g. stdin, text file, pipe, ...). The line will be stored in pattern buffer, at which SED commands will be executed.
2.
Execute: Execute SED commands in pattern space.
3.
Display: Display the result of execution to stdout.
Basic syntax
You can use SED in either of two ways; using inline commands or SED script file.
The syntax is as follows:
$ sed [-n] [-e] 'inline commands' # use inline commands
$ sed [-n] -f 'your_sed_script_file' # use SED script file
Shell
복사
(Just think of SED script file as a list of SED commands.)
Supply text which you want to manipulate to SED in various ways.
$ echo 'your_text_here' | sed 'commands' # use pipe
$ sed 'commands' your_text_file.txt # use text file
$ sed 'commands' # use SED session
type_your_text_here
...and so on
(Ctrl-D to exit)
Shell
복사
Options
Let's look at some must-know options.
•
n: No auto-print. By default, the content of the pattern buffer is printed before fetching new line from the text. n option prevents this default printing of pattern buffer unless the explicit print command is provided. Thus, the example below does not show any output.
$ sed -n '' your_text_file.txt # no output
Shell
복사
•
e <command>: Specify the next argument is SED command. With this option, we can specify multiple SED commands within a single call of SED program. The example below substitutes old_pattern with new_pattern, and prints the resulting line which is inside the pattern buffer. Don't worry that you don't know those s and p command now. They'll be covered soon.
$ sed -n -e 's/old_pattern/new_pattern/g' -e 'p' your_text_file.txt
Shell
복사
•
i[SUFFIX]: Edit files in-place. The resulting output of SED will replace the original file. When you specify SUFFIX, backup file will be generated. For the name of the backup file, SUFFIX will be appended to the name of original file. The example below substitutes old_pattern with new_pattern, and replaces your_text_file.txt with substituted lines while saving your_text_file.txt.bak as a backup file.
$ sed -i.bak -n 's/old_pattern/new_pattern/g' your_text_file.txt
Shell
복사
•
WARNING: You should be careful to use this option without SUFFIX since it does not make any backup file.
•
f: Add the content of SED script file to the commands to be executed. Note that you can use e and f option together. Just keep in mind that SED commands are processed in order they specified. Thus, in the second example below, the commands in script file will be invoked first, then the inline command will be invoked.
$ sed -f 'your_SED_script_file' your_text_file.txt
# you can do this, too
$ sed -f 'your_SED_script_file' -e 's/old_pattern/new_pattern/g' your_text_file.txt
Shell
복사
Addressing lines
You might want to manipulate not every lines of the text, but specific lines that you've selected. There are diverse ways in SED to select lines, which can be specified with addresses in SED commands. In this section, we'll deal with the text with line numbers for simplicity's sake.
$ seq 10 > my_text.txt
Shell
복사
The basic form of addressing lines in SED is as below:
[address1[,address2]]
Shell
복사
where address1, address2 can be any of addressing modes explained below.
Number addressing
Simply you can address lines with their line numbers. The first address defines the starting line from which the commands will be executed, and the optional second address defines the last line. Note that both ends are inclusive, and every address is . The example below prints out the third, fourth, and fifth line of the file. For now, just focus on the addressing 3,5, not p which prints the current contents of the pattern buffer.
$ sed -n '3 p' my_text.txt # try this command without -n option. what happens?
Shell
복사
3
Plain Text
복사
$ sed -n '3,5 p' my_text.txt
Shell
복사
3
4
5
Plain Text
복사
Not only can you select consecutive lines, but also every n-th lines.
$ sed -n '1~2 p' my_text.txt # print odd-numbered lines
Shell
복사
1
3
5
7
9
Plain Text
복사
Address 0 cannot be used solely, however, it is allowed to specify stepwise range like below:
$ sed -n '0~3 p' my_text
Shell
복사
3
6
9
Plain Text
복사
Regular expression addressing
Use regular expression to select matching lines.
$ sed -n '/1/ p' my_text.txt # Regular expression addresses should be /regexp/ form
Shell
복사
1
10
Plain Text
복사
When they are used to define the range, it goes a bit tricky.
/regexp1/[,/regexp2/]
Plain Text
복사
The first line containing the pattern that matches regexp1 will be the first line from which the execution of the commands starts. Then sed reads a line, executes commands, and repeat, until the line containing the pattern that matches regexp2. Get the feel of regular expression addressing with examples below:
$ sed -n '/2/,/5/ p' my_text.txt
Shell
복사
2
3
4
5
Plain Text
복사
$ sed -n '/6/,/5/ p' my_text.txt # it looks like an empty range, but...
Shell
복사
6
7
8
9
10
Plain Text
복사
Addressing the last line
Simply select last line with special character '$'.
$ sed -n '$ p' my_text.txt
Shell
복사
10
Plain Text
복사
You might be curious about how to select the last two lines...
Unfortunately, there's no simple answer with pure SED. Go to quizzes and solve tricky problems like this one!
Hybrid addressing
Feel free to mix number addressing and regular expression addressing.
$ sed -n '1,/5/ p' my_text.txt
Shell
복사
1
2
3
4
5
Plain Text
복사
$ sed -n '1,/1/ p' my_text.txt # notice the difference with the example just below
Shell
복사
1
2
3
4
5
6
7
8
9
10
Plain Text
복사
Here again, we can use address 0 when we use hybrid addressing (this is for GNU sed).
$ sed -n '0,/1/ p' my_text.txt
Shell
복사
1
Plain Text
복사
Negation
By appending '!' to address, we can address except that line.
$ sed -n '$! p' my_text.txt
Shell
복사
1
2
3
4
5
6
7
8
9
Plain Text
복사
Advanced addressing (for GNU sed)
It is always good to know fancy ones.
This addressing matches address1 and following N lines.
[address1,[+N]]
Plain Text
복사
$ sed -n '/2/,+3 p' my_text.txt
Shell
복사
2
3
4
5
Plain Text
복사
This addressing matches address1 and following lines until the line number is a multiple of N.
[address1,[~N]]
Plain Text
복사
$ sed -n '/6/,~4 p' my_text.txt
Shell
복사
6
7
8 # 8 is a multiple of 4 :)
Plain Text
복사
Commands manipulating lines
Let's assume my_text.txt file is as below:
One apple
Two banana
Three cat
Four dog
Five elephant
Six frog
Seven gorilla
Plain Text
복사
Print line (p)
We've already seen lots of p commands in examples above. As you can guess, it prints the content of the pattern buffer. Basic syntax of p command is as below:
[address1,[address2]] p
Plain Text
복사
Do you remember -n option? By default, SED prints the content of the pattern buffer before it fetches a new line from text. -n option prevents this auto-printing of pattern buffer. Then, can you guess the output of the following command without -n option?
sed 'p' my_text.txt
Plain Text
복사
One apple
One apple
Two banana
Two banana
Three cat
Three cat
Four dog
Four dog
Five elephant
Five elephant
Six frog
Six frog
Seven gorilla
Seven gorilla
Plain Text
복사
Each line is printed twice, because of SED's default auto-print and p command.
Usually we want this, each line printed once.
$ sed -n 'p' my_text.txt # no auto-print
Shell
복사
One apple
Two banana
Three cat
Four dog
Five elephant
Six frog
Seven gorilla
Plain Text
복사
Print specific lines with addressing.
$ sed -n '2,4 p' my_text.txt
Shell
복사
Two banana
Three cat
Four dog
Plain Text
복사
When p command is used with other commands, it is often hard to expect the output. Just remember: p command prints the current data stored in the pattern buffer.
Delete line (d)
[address1[,address2]] d
Plain Text
복사
Delete line command deletes the data in the pattern buffer.
$ sed '2,5 d' my_text.txt
Shell
복사
One apple
Six frog
Seven gorilla
Plain Text
복사
To understand the example above, again, you should know the principle of SED's auto-print. Because we deleted some lines from the pattern buffer before they are auto-printed, they don't appear in output.
How about this one? Can you guess why there isn't any output?
$ sed -n '2,5 d' my_text.txt
Shell
복사
(No output)
Plain Text
복사
As usual, any kinds of addresses can be specified to select lines to be deleted.
$ sed '/banana/,/frog/ d' my_text.txt
Shell
복사
One apple
Seven gorilla
Plain Text
복사
Quit (q)
[address] q [value]
Plain Text
복사
Quit command makes SED stop processing lines when SED fetches the line specified by the address. Please note that even though SED doesn't fetch the next line any more, it still auto-prints the 'last' line.
$ sed '3 q' my_text.txt
Shell
복사
One apple
Two banana
Three cat # note that this line is printed
Plain Text
복사
Go through these examples below:
We can explain this as 'print(1) - print(2) - print(3) - quit(3)'
$ sed -n -e 'p' -e '3 q' my_text.txt
Shell
복사
One apple
Two banana
Three cat
Plain Text
복사
'print(1) - print(2) - quit(3)' for this one.
$ sed -n -e '3 q' -e 'p' my_text.txt
Shell
복사
One apple
Two banana
Plain Text
복사
'print(1) - auto-print(1) - print(2) - auto-print(2) - print(3) - auto-print(3)' here.
$ sed -e 'p' -e '3 q' my_text.txt
Shell
복사
One apple
One apple
Two banana
Two banana
Three cat
Three cat
Plain Text
복사
This one is tricky, 'print(1) - auto-print(1) - print(2) - auto-print(2) - quit(3) - auto-print(3)'
$ sed -e '3 q' -e 'p' my_text.txt
Shell
복사
One apple
One apple
Two banana
Two banana
Three cat # even though there's '3 q' command, this line is printed because of auto-print
Plain Text
복사
You can specify exit status (or return status) with [value]
$ sed '2 q 17' my_text.txt; echo $? # 'echo $?' echoes the exit status of the last command executed
Shell
복사
One apple
Two banana
17
Plain Text
복사
Substitute (s)
[address1[,address2]] s/old_pattern/new_pattern/[flags]
Plain Text
복사
Substitute command is one of the most powerful features of SED. Substitute command looks for old_pattern within the line stored in the pattern buffer, replaces old_pattern with new_pattern if pattern match succeeds. Note that all of this string manipulation occurs in the pattern buffer, so auto-printing of lines reflects the modifications.
$ sed 's/a/*/' my_text.txt
Shell
복사
One *pple
Two b*nana
Three c*t
Four dog
Five eleph*nt
Six frog
Seven gorill*
Plain Text
복사
Global flag (g): Find every matching pattern in each line
You might notice within a single line, executing s command only replaces the first matching pattern(a's) with e's. Let SED look for the pattern globally within each line with g flag.
$ sed 's/a/*/g' my_text.txt
Shell
복사
One *pple
Two b*n*n*
Three c*t
Four dog
Five eleph*nt
Six frog
Seven gorill*
Plain Text
복사
Print flag (p): Print if modified
The following example shows that if we turn off auto-print, we have to specify explicit print option to print modified result.
$ sed -n 's/a/*/' my_text.txt
Shell
복사
(No output)
Plain Text
복사
Print flag, p, only prints the content of the pattern buffer if pattern match occurs. Thus, the fourth and sixth lines (which contain no a's) are not printed in the following example:
$ sed -n 's/a/*/p' my_text.txt
Shell
복사
One *pple
Two b*nana
Three c*t
Five eleph*nt
Seven gorill*
Plain Text
복사
Case-insensitive flag (i): Be case-insensitive when finding pattern matches
Of course you can match case-insensitive patterns by tweaking your regular expressions a little, however, SED provides a useful case-insensitive flag, i.
$ sed 's/o/*/i' my_text.txt
Shell
복사
*ne apple # 'O' matches the pattern 'o' here
Tw* banana
Three cat
F*ur dog # the second 'o' does not match here...because pattern matching is not global
Five elephant
Six fr*g
Seven g*rilla
Plain Text
복사
Flags can be used together
You can use multiple flags at once.
sed -n 's/o/*/gpi' my_text.txt
Shell
복사
*ne apple
Tw* banana
F*ur d*g
Six fr*g
Seven g*rilla
Plain Text
복사
Substitute with addressing
You can make SED substitute text only if the pattern match occurs. Let's replace e's with *'s in the line which contains 'gorilla'.
$ sed '/gorilla/ s/e/*/g' my_text.txt
Shell
복사
One apple
Two banana
Three cat
Four dog
Five elephant
Six frog
S*v*n gorilla
Plain Text
복사
Delimiters
As you see, we often use forward slash '/' as a delimiter of the substitute command. In fact, we can use any character as a delimiter unless it messes up the syntax. This properties of sed is useful when we are dealing with directory paths. Assume we want to replace the path '/home/dohlee/learn-sed' with the path '/new_home/new_dohlee/learn-sed'.
$ echo '/home/dohlee/learn-sed' > path.txt
Shell
복사
To achieve this without modifying delimiters, we should escape all forward slashes not to make them parsed as delimiters. Then we write our sed command as below:
$ sed 's/\\/home\\/dohlee\\/learn-sed/\\/new_home\\/new_dohlee\\/learn-sed/' path.txt
Shell
복사
/new_home/new_dohlee/learn-sed
Plain Text
복사
It is a bit confusing. It becomes more and more complicated when we want to replace the more complicated path. When we use '|' as a delimiter, forward slashes don't have to be escaped, which makes our SED command more readable.
$ sed 's|/home/dohlee/learn-sed|/new_home/new_dohlee/learn-sed|' path.txt
Shell
복사
/new_home/new_dohlee/learn-sed
Plain Text
복사
Even 'x' can be used as a delimiter (since it is not used in the patterns), but don't abuse like this for your clean and readable code! :)
$ sed 'sx/home/dohlee/learn-sedx/new_home/new_dohlee/learn-sedx' path.txt
Shell
복사
/new_home/new_dohlee/learn-sed
Plain Text
복사
Indexing matched patterns
You can substitute the second occurence of the pattern only in each line by specifying '2' flag. Of course you can extend it to substitute the nth occurence of the pattern in each line.
$ sed 's/e/*/2' my_text.txt # substitute the second 'e' in each line
Shell
복사
One appl*
Two banana
Thre* cat
Four dog
Five *lephant
Six frog
Sev*n gorilla
Plain Text
복사
Think how we can switch the numbers (One, Two, ...) with the ABC words (apple, banana, ...).
You might notice that we should be able to know how to access matched patterns. We can make this by capturing the matched pattern with parentheses '()' in old_pattern, and accessing each of them with '\1', '\2', '\3, ...' in new_pattern.
$ sed 's|\\(\\w\\+\\) \\(\\w\\+\\)|\\2 \\1|' my_text.txt
Shell
복사
apple One
banana Two
cat Three
dog Four
elephant Five
frog Six
gorilla Seven
Plain Text
복사
The regular expression above can be explained as below:
Basically all of the characters have special meanings, so they are escaped by backslash '\'. Just for the simple illustration of the regular expression, we will not think of backslashes from now on. Without backslash, the command can be rewritten like this. (Note that this command is not valid.)
$ sed 's|(w+) (w+)|\\2 \\1|' my_text.txt
Shell
복사
Escaped 'w' is a metacharacter which matches a single word character (alphabet, digits, and underscore). '+' means that the preceeding character appears one or more times consecutively. Thus the regular expression (w+) captures a single word. The whole expression '(w+) (w+)' captures two words separated by a single space. Captured words are accessed by '\1', and '\2', respectively. Finally, by writing new_pattern like '\2 \1', the two words are successfully switched.
Append (a)
[address] a text-to-append
Plain Text
복사
You can append a text after the lines specified by the address. The command below appends a line 'Eight happy' after the fourth line.
$ sed '/Four/ a Eight happy' my_text.txt
Shell
복사
One apple
Two banana
Three cat
Four dog
Eight happy
Five elephant
Six frog
Seven gorilla
Plain Text
복사
By addressing the last line with '$', you can append a line at the end of the file.
$ sed '$ a Eight happy' my_text.txt
Shell
복사
One apple
Two banana
Three cat
Four dog
Five elephant
Six frog
Seven gorilla
Eight happy
Plain Text
복사
Translate (y)
[address1[,address2]] y/from-list/to-list/
Plain Text
복사
The characters in from-list is translated into to-list. The length of from-list and to-list should be equal, so that the command means intuitive one-to-one mapping of characters.
The command below converts 'b' into 8, 'e' into 3, 'g' into 9, 'i' into 1, 's' into 5, 't' into 7, and 'o' into 0.
$ sed 'y/begisto/8391570/' my_text.txt
Shell
복사
On3 appl3
Tw0 8anana
Thr33 ca7
F0ur d09
F1v3 3l3phan7
S1x fr09
S3v3n 90r1lla
Plain Text
복사
Although it is not a usual case, it is worth knowing that when the mapping is specified as one-to-many mapping, only the first mapping will be applied.
$ sed 'y/aaaaa/12345' my_text.txt
Shell
복사
One 1pple
Two b1n1n1
Three c1t
Four dog
Five eleph1nt
Six frog
Seven gorill1
Plain Text
복사
Show line numbers (=)
[address1[,address2]] =
Plain Text
복사
One useful feature of sed is that it automatically counts the line number while processing the text file. The line number can be printed by '=' command. Note that we don't suppress auto-printing option in the example below, hence the lines are printed also.
$ sed '=' my_text.txt
Shell
복사
1
One apple
2
Two banana
3
Three cat
4
Four dog
5
Five elephant
6
Six frog
7
Seven gorilla
Plain Text
복사
Only the number of lines which have letter 'o' will be printed in the command below:
sed '/o/ =' my_text.txt
Shell
복사
One apple
2
Two banana
Three cat
4
Four dog
Five elephant
6
Six frog
7
Seven gorilla
Plain Text
복사
Guess what this command is doing:
$ sed -n '$ =' my_text.txt
Shell
복사
7 # prints the number of lines in the file!
Plain Text
복사
Commands manipulating buffers
Replace pattern buffer (n)
[address[,address2]] n
Shell
복사
This command is tricky. So try to understand it carefully. 'n' command basically clears the pattern buffer and fetches the next line. If the suppress auto-print option (-n) is not specified, the content of the pattern buffer is printed before it is cleared.
$ sed 'n' my_text.txt
Shell
복사
One apple
Two banana
Three cat
Four dog
Five elephant
Six frog
Seven gorilla
Plain Text
복사
However, if you suppressed auto-print, the content of the pattern buffer will not be printed.
$ sed -n 'n' my_text.txt
Shell
복사
(No output)
Plain Text
복사
Here follows the trickiest part. So far, the commands that you gave have been applied for every line. However, when 'n' commands are included, the commands following the 'n' command will be executed on the next line the pattern buffer is replaced by the next line. The command below prints every second line.
$ sed -n 'n;p' my_text.txt
Shell
복사
Two banana
Four dog
Six frog
Plain Text
복사
In other words, 'n' commands allows more than one lines to be executed in a single sed cycle.
Append the next line to pattern buffer (N)
[address1[,address2]] N
Plain Text
복사
While 'n' command clears the current pattern buffer and fetches the next line, 'N' command appends the next line to the current pattern buffer. Note that before fetching the next line, newline character is added to the pattern buffer.
$ sed '=;N' my_text.txt
Shell
복사
1
One apple
Two banana
3
Three cat
Four dog
5
Five elephant
Six frog
7
Seven gorilla
Plain Text
복사
When there is no line to fetch, SED exits immediately.
Exchange pattern buffer and hold buffer (x)
The hold buffer is internal SED buffer that is preserved through SED cycles. 'x' command is one of the many ways to fill the hold buffer. The following command prints only the even numbered lines.
$ sed -n 'x;n;p' my_text.txt
Shell
복사
Two banana
Four dog
Six frog
Plain Text
복사
How can we print only the odd numbered lines with just a slight modification?
$ sed -n 'x;n;x;p' my_text.txt
Shell
복사
One apple
Three cat
Five elephant
Shell
복사
In the above command, we just exchange contents of the pattern buffer and the hold buffer before printing. Note that it doesn't print seventh line because 'n' command cannot fetch the next line, so SED terminates before printing.
Without the hold buffer, SED can only produce output which preserves the original order. Now we will start using the hold buffer, so we can modify the order of the file. The command below exchanges the order of adjacent lines.
$ sed 'x;n;p;x;p' my_text.txt
Shell
복사
Two banana
One apple
Four dog
Three cat
Six frog
Five elephant
Plain Text
복사
Copy contents of pattern buffer to hold buffer (h)
[address1[,address2]] h
Plain Text
복사
While 'x' command exchanges the content of the pattern buffer and the hold buffer, 'h' command copies the content of the pattern buffer to the hold buffer. This command is useful when you want to get the line before the line which satisfies the condition. For example, if you want to print lines just before the lines containing 'a'.
$ sed -n '/a/ {x;p;x}; h;' my_text.txt
Shell
복사
# an empty line
One apple
Two banana
Four dog
Six frog
Plain Text
복사
Since the pattern buffer is empty at first, only newline character is printed for the first line.
Append contents of pattern buffer to hold buffer (H)
[address1[,address2]] H
Plain Text
복사
'H' command appends data from the pattern buffer to the hold buffer. The contents of the hold buffer will be separated by newline character. The following command saves the lines containing 'a' to the hold buffer, and finally prints those lines which are separated by the pipe character.
$ sed -n '/a/ H; $ {x;s/\\n/|/g;p}' my_text.txt
Shell
복사
|One apple|Two banana|Three cat|Five elephant|Seven gorilla
Plain Text
복사
Copy contents of hold buffer to pattern buffer (g)
[address1[,address2]] g
Plain Text
복사
So far, we had to use exchange command, 'x', to get data from the hold buffer to the pattern buffer. However, when you don't mind losing current data of the pattern buffer and just want to get the contents of the hold buffer while preserving the hold buffer, it might be troublesome with exchange command. Because you have to exchange the content with 'x', print it with 'p', and restore the hold buffer with 'x'. In this case, copying the hold buffer to the pattern buffer will be convenient. 'g' command does this.
$ sed -n 'H; /t/ {g;p}' my_text.txt
Shell
복사
# an empty line
One apple
Two banana
Three cat
# an empty line
One apple
Two banana
Three cat
Four dog
Five elephant
Plain Text
복사
Executing the command above prints the contents of the hold buffer when SED meets line containing 't'. You might notice that the contents are printed in accumulative way.
Append contents of hold buffer to pattern buffer (G)
[address1[,address2]] G
Shell
복사
This command is just the reverse command of 'H' command. It appends the contents of the hold buffer to the pattern buffer. Can you predict the output of the following command?
$ sed -n '1! G; x; $ {g;p}' my_text.txt
Shell
복사
Seven gorilla
Six frog
Five elephant
Four dog
Three cat
Two banana
One apple
Plain Text
복사
It reverses the order of lines in the file! Let me explain the command step by step.
1.
'1! G' command makes SED append the contents of the hold buffer to pattern buffer at every line except first line.
2.
Then SED executes 'x' command to exchange the contents of the hold buffer and the pattern buffer. Consequently, after executing every 'x' command, the reverse-ordered lines will be stored in hold buffer.
3.
Finally, SED executes '$ {g;p}' command only at the last line of the file. SED copies the hold buffer to the pattern buffer, and prints it. The text is printed in reverse order.